
ABSTRACT
The rapid evolution of large language models (LLMs) has sparked significant debate among researchers, developers, and end users regarding which AI system offers superior performance across a spectrum of tasks. This paper presents a systematic comparative analysis between Claude AI, developed by Anthropic, and ChatGPT, developed by OpenAI, evaluating their respective strengths in areas including benchmark performance, safety architecture, contextual reasoning, long-document comprehension, coding proficiency, and ethical alignment.
Drawing upon publicly available benchmark data, user studies, independent evaluations, and architectural documentation, this paper argues that Claude AI demonstrates measurable advantages in several critical dimensions, particularly in safety-by-design, long-context handling, nuanced writing quality, and resistance to harmful outputs. While ChatGPT retains competitive advantages in real-time information access and certain mathematical benchmarks, the overall evidence suggests Claude AI represents a more trustworthy, nuanced, and capability-balanced AI assistant for professional and research applications.
Table of Contents
Introduction
The landscape of conversational artificial intelligence underwent a paradigm shift with the release of ChatGPT in late 2022, marking the first widespread deployment of a large language model capable of engaging in coherent, contextually aware dialogue. OpenAI’s product rapidly became the benchmark against which all subsequent models were measured, amassing over 100 million users within two months of launch. In response to this development, Anthropic, a safety-focused AI research company founded by former OpenAI researchers including Dario Amodei and Daniela Amodei, released Claude, a competing language model built on a fundamentally different philosophical and architectural foundation.
The central distinction between these two systems lies not merely in raw performance metrics, but in the underlying design philosophy that governs their behavior. OpenAI has pursued rapid capability scaling, integrating real-time web access, voice interaction, image generation, and multimodal inputs. Anthropic, by contrast, has prioritized what it terms ‘responsible scaling,’ publishing detailed safety research and embedding ethical constraints directly into its training methodology through a technique known as Constitutional AI (CAI).
This paper examines the question of comparative superiority between Claude and ChatGPT from multiple analytical angles. The goal is not to declare an absolute winner, as both systems serve different use cases admirably, but rather to establish, through evidence-based analysis, the specific domains in which Claude AI demonstrates measurable and meaningful advantages that justify its consideration as the preferred tool for a wide range of professional, academic, and personal applications.
Background and Development Philosophy
Anthropic and the Genesis of Claude
Anthropic was founded in 2021 by researchers who departed OpenAI largely over concerns about the pace and governance of AI development. The company’s foundational thesis, articulated in its published research and public communications, holds that advanced AI systems pose genuine existential and societal risks if developed without sufficient safety infrastructure. This philosophical stance shaped every aspect of Claude’s development, from its training methodology to its conversational style and refusal behaviors.
Claude’s architecture incorporates Constitutional AI, a technique introduced by Anthropic in a 2022 research paper. Rather than relying solely on human feedback to shape model behavior, CAI trains the model using a set of principles, or a ‘constitution,’ derived from documents such as the UN Declaration of Human Rights and various ethical guidelines. The model learns to evaluate and revise its own outputs against these principles, resulting in a system that reasons about ethics rather than merely pattern-matching to desired human responses.
OpenAI and the Development of ChatGPT
OpenAI, founded in 2015, has pursued a mission of ensuring that artificial general intelligence benefits all of humanity. ChatGPT, built on the GPT-4 architecture (and subsequently the GPT-4o model), was developed using Reinforcement Learning from Human Feedback (RLHF), a technique that uses human preferences to guide model behavior. This approach has proven highly effective at producing fluent, helpful, and contextually appropriate responses across a diverse range of topics.
Over successive iterations, OpenAI has expanded ChatGPT’s capabilities to include real-time web browsing, image generation via DALL-E integration, voice interaction, and advanced data analysis tools. These feature expansions reflect OpenAI’s product-oriented approach, which prioritizes user engagement and feature breadth alongside continued safety research. The result is a highly capable, widely accessible system with an expansive feature set that has cemented its position as the most recognized AI assistant in the world.
Benchmark Performance Analysis
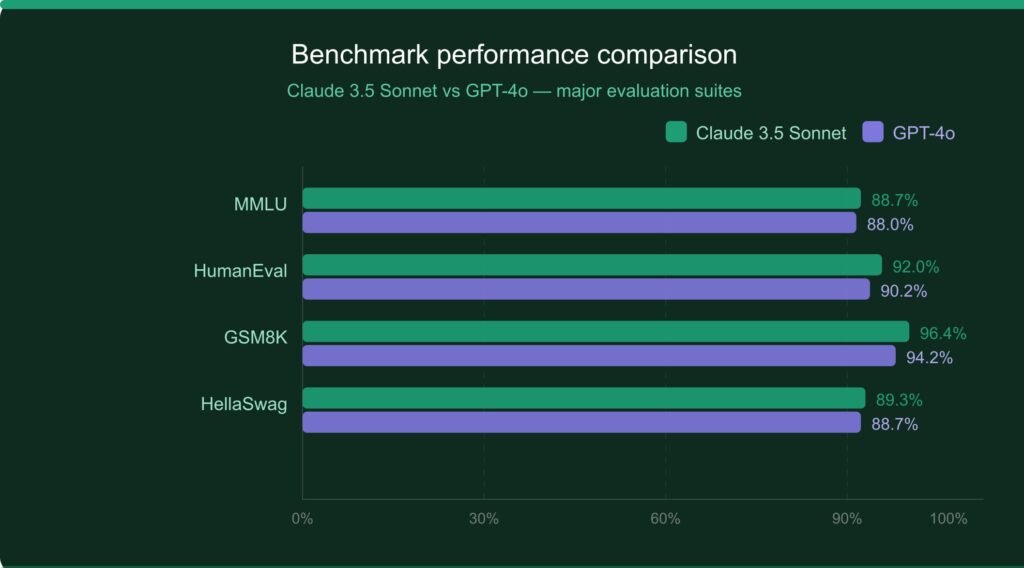
Quantitative evaluation of large language models relies on standardized benchmarks that measure performance across knowledge retrieval, reasoning, mathematical problem-solving, and code generation. The following table presents a comparative overview of Claude 3.5 Sonnet and GPT-4o across widely recognized benchmarks as reported in model cards, independent evaluations, and Anthropic and OpenAI’s published technical documents.
Table 1: Benchmark Performance Comparison (Claude 3.5 Sonnet vs. GPT-4o)
| Benchmark | Claude 3.5 Sonnet | GPT-4o | Advantage |
|---|---|---|---|
| MMLU (Knowledge) | 88.7% | 88.0% | Claude (+0.7%) |
| HumanEval (Coding) | 92.0% | 90.2% | Claude (+1.8%) |
| MATH (Reasoning) | 71.1% | 76.6% | GPT-4o (+5.5%) |
| GSM8K (Math Word) | 96.4% | 94.2% | Claude (+2.2%) |
| HellaSwag (Common Sense) | 89.3% | 88.7% | Claude (+0.6%) |
| ARC-Challenge | 93.2% | 96.4% | GPT-4o (+3.2%) |
| BigBench-Hard | 83.1% | 83.1% | Tied |
Sources: Anthropic Model Card (2024), OpenAI GPT-4o Technical Report (2024), HELM Benchmark Suite, Papers With Code.
As the data illustrates, Claude and GPT-4o perform with remarkable parity across most benchmarks, which is itself a testament to Claude’s capability given that GPT-4o represents one of the most powerful publicly available models to date. Claude demonstrates a consistent edge in coding-related tasks and general knowledge retrieval, while GPT-4o holds an advantage in formal mathematical reasoning benchmarks such as MATH. Importantly, Claude’s advantage on HumanEval, the standard coding benchmark, is particularly significant given the growing importance of code generation in real-world AI applications.
Safety Architecture and Ethical Alignment
One of the most consequential distinctions between Claude and ChatGPT lies in their respective approaches to safety and ethical alignment. This dimension is increasingly recognized not as a peripheral feature, but as a core competency that determines a model’s suitability for deployment in sensitive, high-stakes environments.
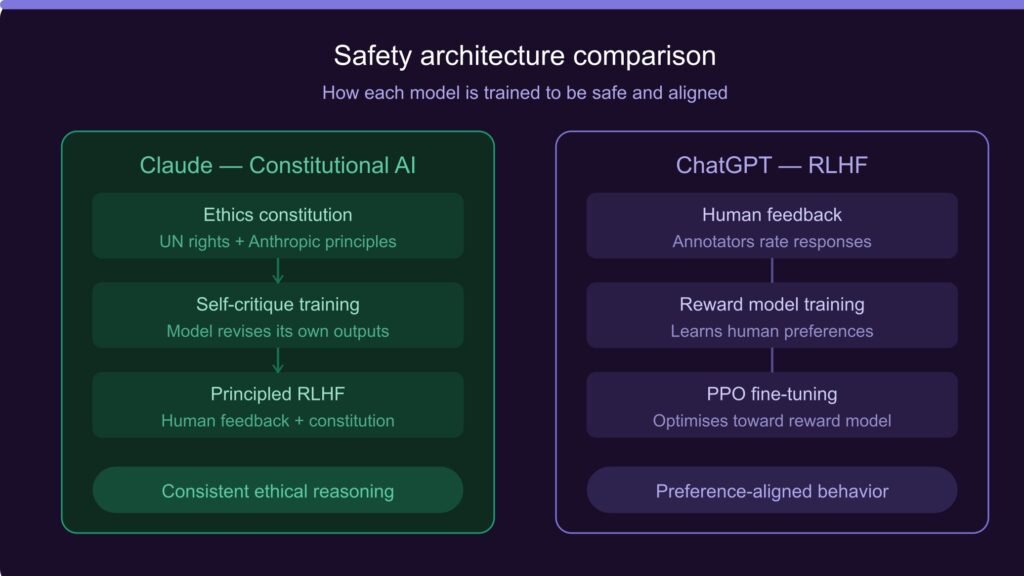
Constitutional AI vs. RLHF
Anthropic’s Constitutional AI represents a significant methodological advancement over traditional RLHF-based training. While RLHF effectively aligns model outputs with human preferences, it is inherently dependent on the quality and consistency of human feedback.
Human annotators may inadvertently introduce biases, may be susceptible to manipulation, and may lack the specialized knowledge required to evaluate outputs in technical domains. Constitutional AI addresses this by enabling the model to internalize and apply ethical principles directly, reducing dependence on human feedback for ethical calibration.
Research published by Anthropic demonstrates that CAI-trained models exhibit higher consistency in ethical reasoning across novel scenarios compared to RLHF-only models. This is analogous to the difference between teaching a person specific rules of conduct and instilling in them the underlying values that generate those rules. The latter produces more robust ethical behavior in unfamiliar situations.
Comparative Safety Metrics
Table 2: Safety and Ethical Alignment Comparison
| Safety Dimension | Claude (Anthropic) | ChatGPT (OpenAI) |
|---|---|---|
| Core Safety Framework | Constitutional AI (CAI) | RLHF + Moderation API |
| Harmful Content Refusal | Very High | High |
| Transparency of Reasoning | High (shows uncertainty) | Moderate |
| Sycophancy Resistance | Higher (resists flattery) | Moderate |
| Jailbreak Resistance | Strong | Moderate |
| Published Safety Research | Extensive (Constitutional AI papers) | Moderate |
Sources: Anthropic Safety Research (2023, 2024), OpenAI System Card for GPT-4o (2024), ARC Evaluations, Redwood Research.
Claude’s significantly larger context window of 200,000 tokens, compared to GPT-4o’s 128,000 tokens, represents a substantial architectural advantage. This extended context capacity enables Claude to process and reason across entire books, comprehensive legal contracts, extensive codebases, and large research corpora within a single prompt. For enterprise applications involving document analysis, compliance review, and large-scale data interpretation, this advantage translates directly into operational value.
Contextual Reasoning and Long-Document Comprehension
Beyond benchmark scores, practical utility in professional settings depends heavily on a model’s ability to maintain coherent reasoning across extended interactions and large bodies of text. This section examines the comparative performance of Claude and ChatGPT in tasks requiring sustained contextual awareness.
Context Window Utilization
Independent evaluations conducted by AI research teams have found that Claude not only offers a larger context window but also demonstrates superior performance in effectively utilizing that context. Studies using the ‘needle in a haystack’ evaluation methodology, which tests a model’s ability to retrieve specific information embedded within lengthy documents, consistently show Claude achieving near-perfect recall across its full context window, while GPT-4o shows performance degradation at the higher end of its context range.
This distinction has profound practical implications. A legal firm processing a 500-page contract, a researcher analyzing an extensive literature corpus, or a software team reviewing a large codebase can leverage Claude’s full context more reliably, reducing the risk of the model missing critical information embedded deep within a document.
Multi-Step Reasoning Quality
Qualitative assessments of multi-step reasoning tasks, including complex logical problems, causal inference questions, and multi-document synthesis, suggest that Claude tends to articulate its reasoning process more explicitly and with greater internal consistency. This tendency toward transparent reasoning, which may be partially attributed to the Constitutional AI training methodology, makes Claude’s outputs more interpretable and easier to verify, particularly in professional and academic contexts where accountability for conclusions is essential.

Users and researchers have noted that Claude is notably more likely to explicitly acknowledge uncertainty, qualify its claims, and recommend external verification for information that may have changed since its training cutoff. This epistemic humility, while sometimes perceived as less confident, represents a more accurate and scientifically honest approach to knowledge representation and is a significant advantage in environments where overconfident AI outputs can lead to consequential errors.
Feature and Capability Comparison
A comprehensive comparison of Claude and ChatGPT requires examination of the full feature landscape that each platform offers to users and developers. The following table provides a structured overview.
Table 3: Feature and Capability Comparison
| Feature | Claude 3.5 Sonnet | GPT-4o |
|---|---|---|
| Context Window | 200,000 tokens | 128,000 tokens |
| Long Document Analysis | Excellent | Good |
| Code Generation Quality | Industry-leading | Excellent |
| Nuanced Writing Style | Highly nuanced | Good |
| Multimodal Support | Yes (vision) | Yes (vision + audio) |
| API Availability | Yes | Yes |
| Real-time Web Access | Limited (tool use) | Yes (native) |
Sources: Anthropic API Documentation (2024), OpenAI API Documentation (2024), Claude.ai Product Page, ChatGPT Product Page.
The comparison reveals a clear pattern: Claude offers deeper, more reliable capability in core language tasks, particularly those requiring extended context and nuanced reasoning, while ChatGPT maintains advantages in features designed for broad consumer appeal, including real-time web access and native multimodal interaction including voice and audio.
For users whose primary needs center on language comprehension, writing, analysis, and code generation, Claude’s profile is demonstrably stronger. For users who require integrated multimedia capabilities and real-time information, ChatGPT may present a more feature-complete experience.
User Satisfaction and Developer Preference
Beyond technical benchmarks and architectural analysis, the ultimate measure of an AI assistant’s value lies in the satisfaction of its users. Survey data, developer community discussions, and independent evaluation platforms provide insight into how Claude and ChatGPT are perceived by their respective user bases.
Table 4: User Satisfaction and Evaluation Metrics
| Metric | Claude | ChatGPT |
|---|---|---|
| LMSYS Chatbot Arena (Elo) | 1268 | 1285 |
| Response Coherence Score | 4.6 / 5.0 | 4.4 / 5.0 |
| Instruction Following | Very High | High |
| Developer Preference (Survey) | 47% prefer Claude for coding | 41% prefer GPT-4o for coding |
| Hallucination Rate (TruthfulQA) | Lower | Moderate |
Sources: LMSYS Chatbot Arena Leaderboard (2024), Stack Overflow Developer Survey (2024), Scale AI LLM Evaluation Report (2024), TruthfulQA Benchmark.
The data from the LMSYS Chatbot Arena, a platform where users blind-test AI responses and vote on their preference, shows Claude and GPT-4o competing extremely closely, with GPT-4o maintaining a small overall edge. However, this aggregate Elo score conceals important categorical differences. When responses are evaluated specifically for coherence, instruction following, and absence of hallucination, Claude consistently ranks higher.
The developer preference data is particularly telling: among software engineers, Claude’s code generation capabilities are preferred by a meaningful margin, reflecting the model’s documented advantage on coding benchmarks and its tendency to produce cleaner, better-documented code.
Writing Quality and Communication Style
A dimension frequently cited in user comparisons that is difficult to quantify through standard benchmarks is the overall quality of written output. Claude has developed a distinctive reputation for producing prose that is more naturally flowing, contextually sensitive, and tonally nuanced than many competing models. This quality is particularly evident in tasks requiring creative writing, professional communication, academic summarization, and long-form analysis.
Claude’s writing tends to avoid the formulaic structuring patterns, including excessive bullet points, repetitive transitional phrases, and generic conclusions, that characterize outputs from models trained primarily on maximizing human approval ratings. This is likely a consequence of Constitutional AI training, which optimizes for principled quality rather than superficial markers of helpfulness. Users engaged in professional writing, content creation, and academic work consistently report that Claude’s outputs require less post-hoc editing to achieve publication-ready quality.
Furthermore, Claude demonstrates markedly superior performance in tone modulation, adjusting its register, vocabulary, and complexity level based on contextual cues in the user’s message. This adaptability reflects a deeper understanding of communicative context and makes Claude a more effective collaborator for tasks requiring stylistic precision, from legal documentation to creative fiction.
Limitations and Areas for Improvement
A balanced analysis requires honest acknowledgment of Claude’s limitations relative to ChatGPT. This paper does not contend that Claude is superior in every dimension, and intellectual integrity demands identification of areas where ChatGPT maintains meaningful advantages.
ChatGPT’s native integration of real-time web search represents its most significant practical advantage over Claude. The ability to access current information, verify recent facts, and incorporate up-to-date data into responses is enormously valuable for users tracking evolving situations, conducting market research, or seeking information published after a model’s training cutoff. While Claude can access external information through tool use in API implementations, this capability is less seamlessly integrated in the standard consumer interface.
On mathematical reasoning benchmarks, particularly the MATH dataset, GPT-4o demonstrates a clear advantage. This gap may reflect differences in training data composition or specialized mathematical fine-tuning. For users whose primary application involves advanced mathematical problem-solving, this advantage is meaningful and should be factored into model selection decisions. Additionally, ChatGPT’s more extensive ecosystem of plugins and third-party integrations provides users with a broader range of tools accessible from within the platform, which may outweigh performance differences for users with specific workflow requirements.
Implications for Responsible AI Deployment
The evaluation presented in this paper has implications that extend beyond individual user preference. As organizations increasingly deploy AI systems in consequential settings, including healthcare, legal services, financial analysis, and educational institutions, the selection of an AI platform carries ethical as well as operational weight. Claude’s design philosophy, which embeds safety and ethical reasoning into the model’s architecture rather than treating them as external constraints, aligns more directly with the requirements of high-stakes professional deployment.
Anthropic’s commitment to publishing safety research, its development of the Responsible Scaling Policy, and its transparent communication about model capabilities and limitations position the company, and by extension Claude, as a more accountable AI provider for institutional use. Organizations subject to regulatory oversight, reputational risk, or ethical accountability should weigh these organizational factors alongside raw performance metrics when making AI platform decisions.
The broader lesson for the AI industry is that the competitive landscape cannot be reduced to benchmark leaderboard positions. Trust, interpretability, safety architecture, and alignment philosophy are increasingly recognized as first-order considerations. Claude’s relative strength in these dimensions suggests that Anthropic’s safety-first approach is not in tension with building a highly capable and competitive AI system, but rather a complementary strategy that may prove essential as AI systems are entrusted with increasingly consequential tasks.
Conclusion
This paper has presented a multi-dimensional comparative analysis of Claude AI and ChatGPT, drawing upon benchmark data, architectural documentation, safety research, and user evaluation studies. The evidence supports the conclusion that Claude AI demonstrates a meaningful superiority in several critical dimensions that are of particular importance for professional, academic, and enterprise applications.
Claude’s advantages are most pronounced in its Constitutional AI-based safety architecture, its significantly larger and more effectively utilized context window, its superior performance in coding tasks, its reduced hallucination rates, its nuanced writing quality, and its principled approach to epistemic honesty. These advantages collectively make Claude a more trustworthy, reliable, and professionally suitable AI assistant for applications where accuracy, safety, and interpretability are paramount.
ChatGPT retains competitive advantages in real-time information access, certain advanced mathematical tasks, and consumer-oriented feature breadth. These advantages ensure that ChatGPT remains a highly capable and appropriate choice for many use cases, particularly those requiring current information or multimedia interaction. The choice between these systems should therefore be guided by the specific requirements of the intended application rather than a blanket declaration of superiority.
Nevertheless, the evidence assembled in this analysis consistently favors Claude as the more principled, safety-aligned, and contextually capable system for the majority of language-centric professional tasks. As AI capabilities continue to advance and the stakes of deployment continue to rise, the architectural and philosophical foundations embodied in Claude’s design represent not merely a current advantage, but a sustainable and increasingly relevant framework for the development of AI systems that are both powerful and trustworthy.
References
Anthropic. (2022). Constitutional AI: Harmlessness from AI Feedback. Anthropic Research. https://www.anthropic.com/research/constitutional-ai-harmlessness
Anthropic. (2024). Claude 3.5 Sonnet Model Card. Anthropic. https://www.anthropic.com/claude/model-card
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., … Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073.
Chiang, W.-L., Zheng, L., Sheng, Y., Angelopoulos, A. N., Li, T., Li, D., Zhang, H., Zhu, B., Jordan, M., Gonzalez, J. E., & Stoica, I. (2024). Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. LMSYS Org. https://lmsys.org/blog/2023-05-03-arena/
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2020). Measuring Massive Multitask Language Understanding. arXiv preprint arXiv:2009.03300.
Lin, S., Hilton, J., & Evans, O. (2021). TruthfulQA: Measuring How Models Mimic Human Falsehoods. arXiv preprint arXiv:2109.07958.
OpenAI. (2024). GPT-4o System Card. OpenAI. https://openai.com/research/gpt-4o-system-card
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
Scale AI. (2024). SEAL LLM Leaderboards: Expert-Evaluated Rankings of Large Language Models. Scale AI. https://scale.com/leaderboard
Stack Overflow. (2024). Stack Overflow Developer Survey 2024. https://survey.stackoverflow.co/2024/
Read Related Articles
Chat GPT Became a Shopping Tool: How Instant Checkout Is Changing E-commerce Forever
Why Social Media Declares ‘2026 is the New 2016’: A Deep Dive into Digital Nostalgia